Top AI models cost more because compute is scarce, reasoning burns hidden tokens, and real users now compete for stable capacity.
Why does this feel so strange?
For years, we were trained to believe one thing about technology: the more people use it, the cheaper it gets.
That logic works for many software products. It does not fully work for frontier AI. A PDF tool can serve one more user at almost zero marginal cost. A top AI model cannot. Every serious request still eats compute. A long coding task eats more. A video generation task eats even more. A reasoning model may look clean on screen, but it can burn a lot of hidden work before it gives you the final answer.
OpenAI says reasoning tokens are not visible through the API, but they still occupy context space and are billed as output tokens. So a short answer can hide a long internal bill. That is one reason users feel that AI is getting more expensive, even when the visible output has not become longer.
In short, the problem is not that AI forgot how to get cheaper. The problem is that we are now asking AI to do harder work.
Why are cheap models getting cheaper, while top models stay expensive?
The AI market is splitting into two layers.
| Layer | What is Happening | Market Implications |
|---|---|---|
| Commodity AI | Integration of small models, legacy versions, and basic tasks like rewriting, tagging, and data extraction. | Prices are falling as supply becomes ubiquitous and the complexity of these tasks remains low. |
| Frontier AI | Focus on complex reasoning, advanced coding, autonomous agents, long-context windows, and multimodal/video work. | Prices stay high because demand is surging while hitting a physical "compute wall" (hardware and energy limits). |
OpenAI’s pricing page already shows this split clearly. GPT 5.5 is priced at $2.50 per million input tokens and $15 per million output tokens, while GPT 5.5 pro jumps to $15 per million input tokens and $90 per million output tokens. Anthropic’s Claude Opus 4.7 also sits in the premium range, at $5 per million input tokens and $25 per million output tokens. In other words, AI is not simply getting more expensive or cheaper across the board. It is splitting into layers. Regular models will keep getting cheaper because they handle basic tasks like rewriting, tagging, and extraction. Top models will stay expensive because they handle code, agents, long context, complex reasoning, and multimodal work.
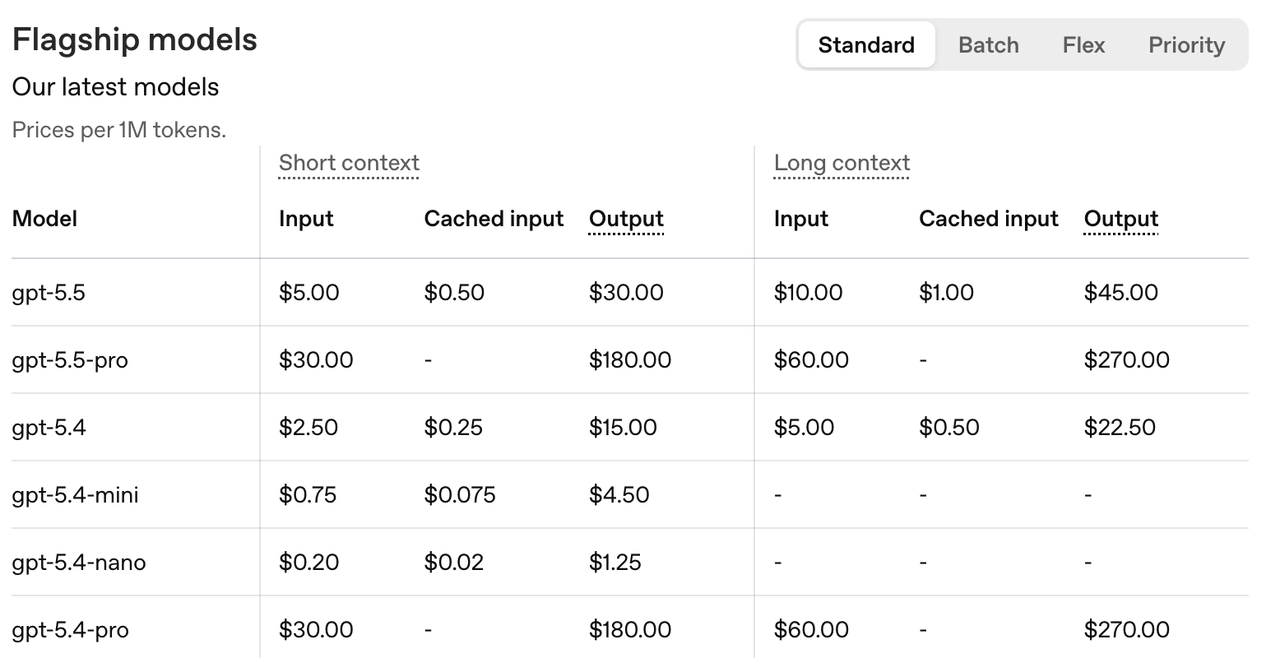
OpenAI’s pricing page
Why can a price increase be a good sign?
I know users hate price increases. I hate them too when I am the one paying.
But I will say something a little unpopular: in my view, a top model being able to raise prices can be a good sign.
- If a model has no users, its compute sits there. It can stay cheap. It can give coupons. It can even look generous.
- If a model reaches real industry quality, people rush in. Developers use it for coding. Creators use it for videos. Companies use it for workflows. Suddenly the cheap price becomes a problem.
- If everyone crowds into the same model at the same low price, the product does not stay magical. It gets slow, unstable, and sometimes stupid.
This is why I do not see every price increase as pure greed. Some of it is monetization, sure. Some of it is the end of subsidies. But some of it is just the market admitting that the model is actually useful.
A model that nobody needs can be cheap forever. A model that people rely on must decide who gets stable capacity.
Why is compute like a power plant?
The big model business has one simple truth: compute is the hard constraint.
I like to compare AI to a power plant. Imagine a power plant can serve 10,000 homes. Then 50,000 homes show up overnight. The plant cannot expand in one week. What happens next?
Everyone gets a worse experience.
That is what people call model degradation, slow response, rate limits, account restrictions, or random instability. The label changes. The root problem is the same. Too many people are pulling from the same limited supply.
NVIDIA’s Q4 fiscal 2026 results make the demand visible. NVIDIA reported record quarterly revenue of $68.1 billion, up 73% year over year. Its Data Center revenue reached $62.3 billion, up 75% year over year. This is not abstract hype. This is the hardware market showing how hungry AI demand has become.
The energy side tells the same story. The International Energy Agency projects global data center electricity consumption to double to about 945 TWh by 2030. It expects data center electricity use to grow around 15% per year from 2024 to 2030, more than four times faster than electricity demand from other sectors.
In short, AI pricing is not only about software. It is about chips, electricity, cooling, networking, storage, and the queue for all of them.
Why does video generation make the price shock worse?
Text hides waste. Video exposes it.
When a text model fails, you regenerate a paragraph. It feels cheap. When a video model fails, you may lose seconds of high resolution generation. You may try ten prompts, keep one clip, and throw away the rest. That waste is part of the real cost.
TechNode reported that ByteDance’s Seedance 2.0 pure video generation costs about 1 yuan, or roughly $0.14, per second, and that a 15 second video consumes about 308,880 tokens.
That number explains why creators feel the price jump in their hands. A 15 second clip is not just 15 seconds. It is motion, consistency, camera movement, character control, resolution, and failed attempts. If you are making a short drama, ad, music video, or game asset, you are not paying for one perfect output. You are paying for exploration.
The key difference between text AI and video AI is not only the file type. It is the cost of trial and error.
Why did early AI feel cheaper than it really was?
A lot of early AI pricing was not real pricing. It was land grabbing.
Platforms used cheap access to attract users, developers, and creators. This is normal internet strategy. First you make the product easy to try. Then, once usage becomes serious, you segment users and charge for stability.
There is nothing mysterious here. The same thing happened in cloud, ride hailing, food delivery, creator tools, and SaaS. Cheap entry brings volume. Heavy usage reveals cost. Business customers then pay for reliability.
The problem is that many AI users confused promotional pricing with permanent pricing.
In short, early cheap tokens were not proof that intelligence had no cost. They were a customer acquisition tool.
Why should limited compute go to real work first?
This is where I have a stronger opinion.
If compute is limited, I would rather see stable capacity go to people doing real work than have everyone share a degraded product equally.
- A casual user may care most about saving a few dollars.
- A professional creator cares more about delivery time.
- A developer cares more about stable latency and predictable output.
- A business team cares more about not breaking a workflow in production.
This is not moral judgment. It is market sorting.
If an AI video creator needs to deliver to a client tomorrow, cheap but unavailable is useless. If an engineering team depends on a coding model to ship, a lower price means little when the model is slow or rate limited. For serious users, stability is not a luxury. It is the product.
That is why I think top model pricing will become more honest. The best models will not be priced like toys forever. They will be priced like infrastructure.
How should API buyers react instead of just complaining?
Complaining is easy. Cost control is harder.
The real question is not whether every model should be cheap. The real question is whether every task deserves the most expensive model.
| Task Category | Recommended Model | Strategic Justification |
|---|---|---|
| Simple Rewrite | Small or mid-sized model | Low-risk tasks do not require the high compute costs of frontier models. |
| Data Extraction | Small model (with validation) | Output accuracy can be programmatically verified, making cheaper models more efficient. |
| Long Coding Task | Frontier coding model | High-complexity tasks have a high cost of failure; precision is more valuable than speed. |
| Agent Planning | Strong reasoning model | Flawed initial logic creates compounded downstream costs and "hallucinated" workflows. |
| Video Generation | Top-tier model (Final/High-value) | Failed generations consume significant budget and time; quality is paramount for final shots. |
| Batch Cleaning | Budget model + Batch mode | Large-scale processing prioritizes cost-per-token over real-time latency. |
The key difference between smart API spending and wasteful API spending is routing. Do not send every task to the most expensive model. Do not send every task to the cheapest model either. Send the task to the model that matches the value of the output.
How can PP API help teams push back against rising model costs?
Model prices may rise, but teams still have choices.
PP API is useful here because it turns model access into a routing and cost control problem, not a one vendor dependency. PP API is a unified LLM API platform. It lets teams access models from OpenAI, Anthropic, Google, DeepSeek, Alibaba, and other providers through one interface. The platform uses a compatible format, so teams can switch providers by changing the model name.
That matters when the market becomes volatile. If one provider raises prices, gets rate limited, or becomes unstable, a team should not rebuild its whole stack. It should be able to change the model choice, compare prices, and keep the workflow alive.
PP API supports OpenAI compatible usage, and its quick start guide says developers only need to point the base URL to PP API and use a PP API Key. Its model switching flow only requires changing the model parameter, with examples that move from GPT 5.4 to DeepSeek, Qwen, and Gemini models.
For cost control, PP API provides dashboard views for model usage distribution, usage trends, request distribution, and usage by API Key. Its Usage Logs record each API call, including model name, input tokens, output tokens, spend, and first token latency. Its Token Management feature lets users create API keys, set independent quota limits, and apply model restrictions. For companies, its Space Management feature supports subaccounts, quota allocation, member usage visibility, and admin roles.
So the pitch is not simply “buy cheaper tokens.” That is too shallow.
The better pitch is this: when top models become expensive, you need a control layer. You need one API for all models, stable routing, provider fallback, transparent price comparison, pay as you go billing, no subscription fee, OpenAI SDK compatibility, and enterprise level usage control. PP API is designed for that exact moment.
In short, if AI compute is the new electricity, PP API is not the power plant. It is the switchboard that helps you choose where the power comes from, how much each team can use, and when to move traffic before the lights flicker.
FAQ
Is AI really getting more expensive?
AI is getting cheaper at the commodity layer and more expensive at the frontier layer. Basic tasks can use cheaper models. Hard tasks still need scarce compute, better reasoning, longer context, and stronger reliability.
Why do reasoning models cost more even when the answer is short?
Reasoning models may spend hidden tokens before they answer. OpenAI says these reasoning tokens are not visible through the API, but they occupy context space and are billed as output tokens.
Does a price increase prove that a model is better?
A price increase alone proves nothing. But when usage rises fast and users keep paying, it often means the model has crossed from demo value into work value.
Why do video models feel much more expensive than text models?
Video generation includes motion, resolution, time, and trial and error. TechNode reported that Seedance 2.0 pure video generation costs roughly $0.14 per second, which makes repeated attempts much more visible than text retries.
What is the most practical way to control API spending?
Teams should route tasks by value, set quota limits, monitor spend by model, track failed calls, and compare providers before defaulting to the most expensive model. A unified API layer like PP API can make those controls easier to operate